Reduce thermodynamic infeasible samples
Identify and remove loopy reactions
The loops_enumeration_from_fva function computes 2 times a Flux Variability Analysis (with loopless parameter to False and True) and identifies possible loopy reaction in given model and returns them in a list. Each item in the list is a tuple of a string (reaction ID) and a float (loopy score returned from the function)
ec_cobra_modelis a cobra model objectfraction_of_optimumis a float variable that defines thefraction_of_optimumparameter used influx_variability_analysis
loopy_reactions_fva = loops_enumeration_from_fva(
ec_cobra_model = ec_cobra_model,
fraction_of_optimum = 0.999)
print(loopy_reactions_fva)
[('SUCDi', 994.7794007141794), ('FRD7', 995.0539767141795)]
The loopy_reactions_turned_off_in_pfba function identifies which reactions from the loopy reactions set calculated with the loops_enumeration_from_fva function can be turned off when performing a loopless_solution applied to pFBA results
loopy_cobra_modelis a cobra model object possibly containing loops (default model without any preproccess)loopy_reactionsis a list with loopy_reactions with reactions classified as loopytolis a tolerance value used to classify a numeric change as important or not
turned_off_reactions = loopy_reactions_turned_off_in_pfba(
loopy_cobra_model = ec_cobra_model,
loopy_reactions = loopy_reactions,
tol = 1e-6)
print(turned_off_reactions)
['FRD7']
Now, we know which reaction to turn off in the given model to reduce the thermodynamic infeasible solutions from sampling
ec_cobra_model_frd7_removed = ec_cobra_model.copy()
ec_cobra_model_frd7_removed.reactions.get_by_id("FRD7").bounds = (0, 0)
Quantify the effect of loopy reactions in sampling
First we need to perform sampling to produce 2 sampling arrays: one from the default model and one from the default model but with the FRD7 reaction removed (model with no active loopy reactions).
samples_optgp_default = sample_optgp(
cobra_model = ec_cobra_model,
n_samples = 3000,
thinning = 100,
reaction_in_rows = True)
samples_optgp_frd7_removed = sample_optgp(
cobra_model = ec_cobra_model_frd7_removed,
n_samples = 3000,
thinning = 100,
reaction_in_rows = True)
The get_loopless_solutions_from_samples function calculates the loopless_solution from each sample and saves results into a new numpy 2D array. Note that the new loopless sampling dataframe does not contain uniform samples
samplesis a numpy 2D array of the samplescobra_modelis a cobra model object
samples_default_loopless_solutions = get_loopless_solutions_from_samples(
samples = samples_default,
cobra_model = ec_cobra_model)
samples_frd7_removed_loopless_solutions = get_loopless_solutions_from_samples(
samples = samples_frd7_removed,
cobra_model = ec_cobra_model_frd7_removed)
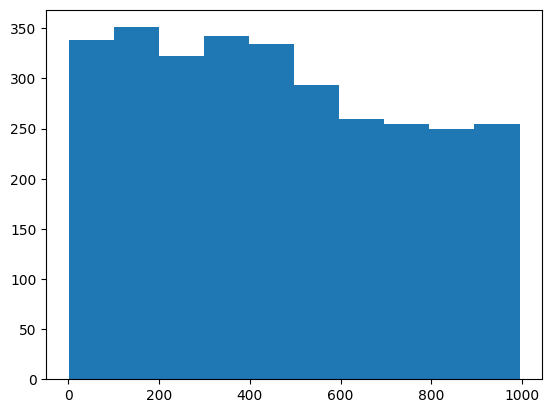
We can also check if the FRD7 loopy reaction affected few or most of the samples. For this, we can calculate the difference across its samples before and after applying the get_loopless_solutions_from_samples function. If FRD7 affected few samples the histogram from these differences would have a peak near 0. If it affected most samples the peak would be far from 0 or the differences distribution would be uniform with a wide range.
change_per_reaction = abs(samples_default) - abs(samples_default_loopless_solutions)
reaction_index = ec_cobra_reaction_ids.index("FRD7")
change_FRD7 = change_per_reaction[reaction_index]
plt.hist(change_FRD7)
plt.show()
In the plot below, we can see a uniform distribution (ranging from 0 to 1000) that validates the effect of FRD7 in sampling results
The calculate_affected_samples function works given the default and the samples from the get_loopless_solutions_from_samples function and identifies how many samples have significant differences. This is done by calculating (for each sample) the distance (change) of the reactions from the given arrays and normalizing by its range. Reactions that have a difference higher than a given threshold are counted and the corresponding sample can potentially be classified as a loopy sample. However, if user does not consider importance when only 1 reaction overcomes this tolerance, he can specify the least number of reactions needed for this classification (e.g 2, 5, 10 …).
initial_samplesis a numpy 2D array of the default samples (before applying theget_loopless_solutions_from_samples)loopless_samplesis a numpy 2D array of the default samples after application of theget_loopless_solutions_from_samplescobra_modelis a cobra model objecttol_reaction_differenceis a tolerance value to classify the difference in reactions before and after theget_loopless_solutions_from_samplesfunction as important or nottol_reactions_countis a tolerance value to classify a sample as loopy based on the least amount of significantly altered reactions
(affected_reactions_count_default,
total_affected_samples_default) = calculate_affected_samples(
initial_samples = samples_default,
loopless_samples = samples_default_loopless_solutions,
cobra_model = ec_cobra_model,
tol_reaction_difference = 0.5,
tol_reactions_count = 1)
(affected_reactions_count_frd7_removed,
total_affected_samples_frd7_removed) = calculate_affected_samples(
initial_samples = samples_frd7_removed,
loopless_samples = samples_frd7_removed_loopless_solutions,
cobra_model = ec_cobra_model,
tol_reaction_difference = 0.5,
tol_reactions_count = 1)
plt.hist(affected_reactions_count_default)
plt.show()
plt.hist(affected_reactions_count_frd7_removed)
plt.show()
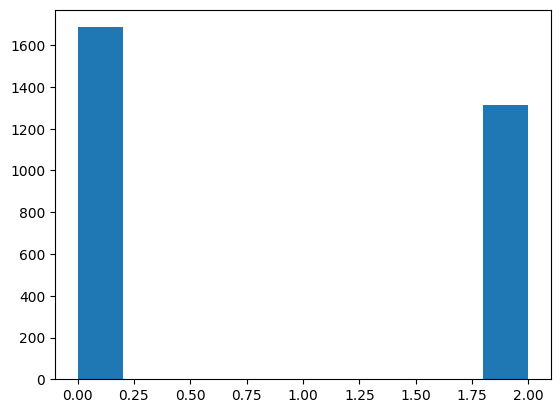
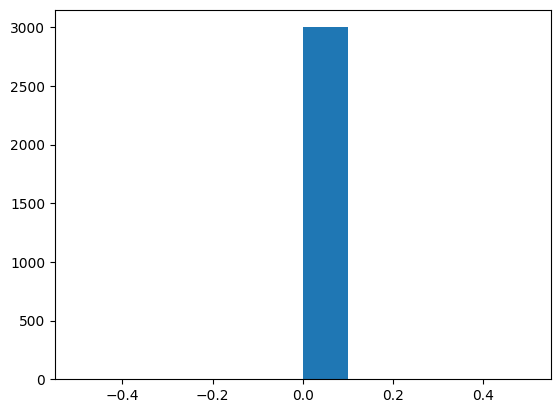
From the above plots, we can see that all samples from the modified model with FRD7 removed are loopless samples (all values at 0). However, samples from the non-modified model have a second peak outside 0, so loops affected them.
The calculate_distances_from_samples function is an alternative approach to quantify the thermodynamic infeasible samples. This function calculates the euclidean distance between a sampling dataset before and after applying the get_loopless_solutions_from_samples. Distances are calculated between different samples, so if user has 3000 samples, he will end up with 3000 distances.
initial_samplesis a numpy 2D array of the default samples (before applying theget_loopless_solutions_from_samples)loopless_samplesis a numpy 2D array of the default samples after application of theget_loopless_solutions_from_samplescobra_modelis a cobra model object
distances_array_samples_default = calculate_distances_from_samples(
initial_samples = samples_default,
loopless_samples = samples_default_loopless_solutions,
cobra_model = ec_cobra_model)
distances_array_samples_frd7_removed = calculate_distances_from_samples(
initial_samples = samples_frd7_removed,
loopless_samples = samples_frd7_removed_loopless_solutions,
cobra_model = ec_cobra_model)
The violin_plot_samples_distances function creates a violin plot from a given distances array
distances_arrayis a numpy 1D array of either the reactions’ or samples’ euclidean distances before and after theget_loopless_solutions_from_samplestitleis the title for the plotexponentformatis a parameter used to determine the numeric scientific notation in the plot (determines a formatting rule for the tick exponents). Available options: “e”, “E”, “power”, “SI”, “B”
violin_plot_samples_distances(
distances_array = distances_array_samples_default,
title = "",
exponentformat = "none")
violin_plot_samples_distances(
distances_array = distances_array_samples_frd7_removed,
title = "",
exponentformat = "none")
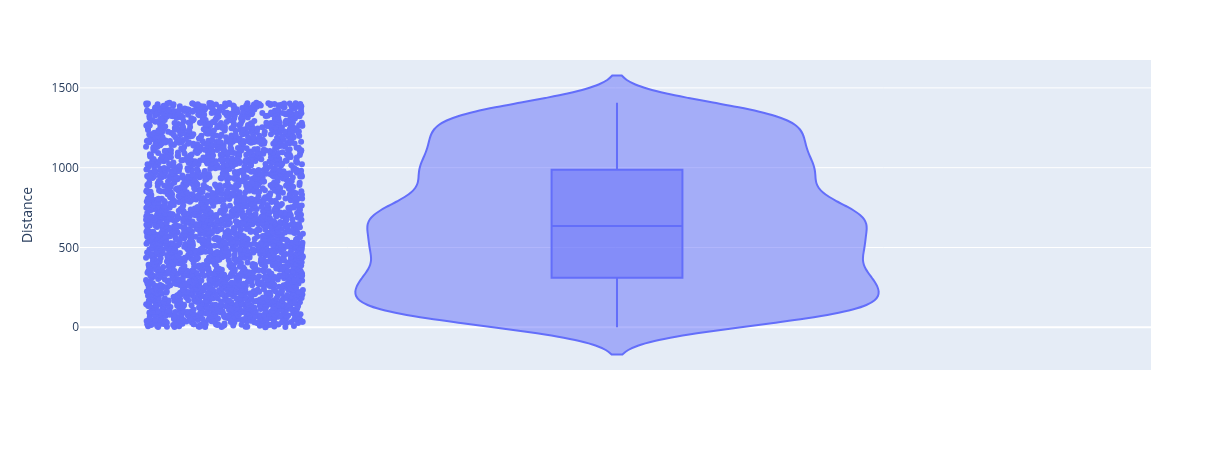
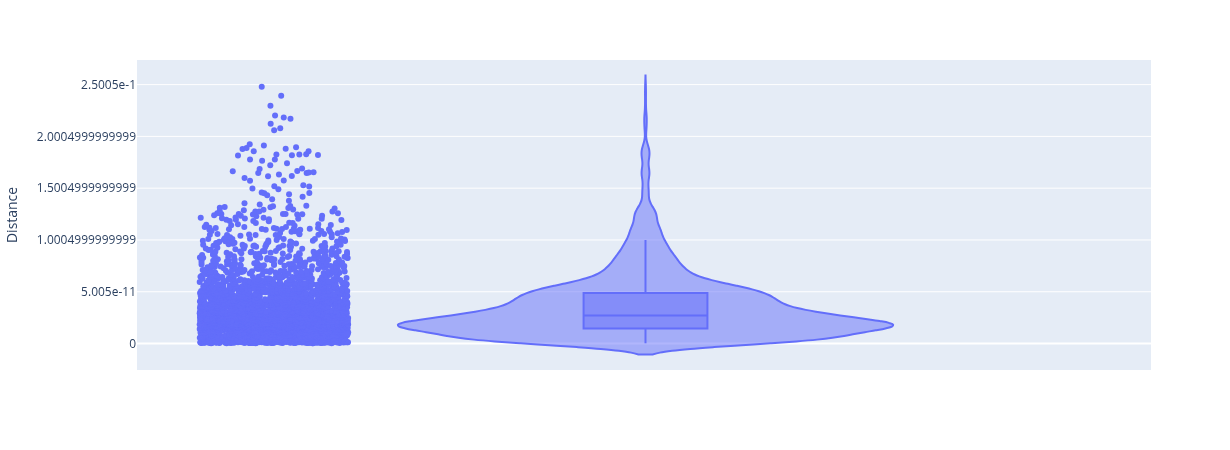
From the above plots, we observe that most samples from the modified model with FRD7 removed, have a 0 distance with themselves after applying the get_loopless_solutions_from_samples function. This is not the case for samples of the default (non-modified) model, which have a distances distribution shifted to significantly greater values.
The calculate_distances_from_reactions function calculates the euclidean distance between a sampling dataset before and after applying the get_loopless_solutions_from_samples. Distances are calculated between different reactions, so if user provides samples of 100 reactions, he will end up with 100 distances.
initial_samplesis a numpy 2D array of the default samples (before applying theget_loopless_solutions_from_samples)loopless_samplesis a numpy 2D array of the default samples after application of theget_loopless_solutions_from_samplescobra_modelis a cobra model object
distances_array_reactions_default = calculate_distances_from_reactions(
initial_samples = samples_default,
loopless_samples = samples_default_loopless_solutions,
cobra_model = ec_cobra_model)
distances_array_reactions_frd7_removed = calculate_distances_from_reactions(
initial_samples = samples_frd7_removed,
loopless_samples = samples_frd7_removed_loopless_solutions,
cobra_model = ec_cobra_model)
violin_plot_samples_distances(
distances_array = distances_array_reactions_default,
title = "",
exponentformat = "none")
violin_plot_samples_distances(
distances_array = distances_array_reactions_frd7_removed,
title = "",
exponentformat = "none")
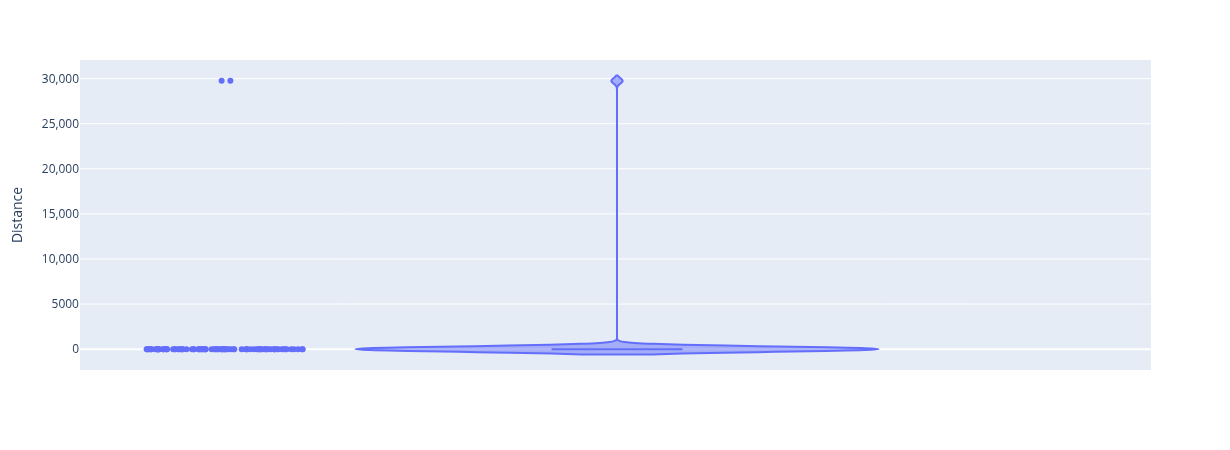
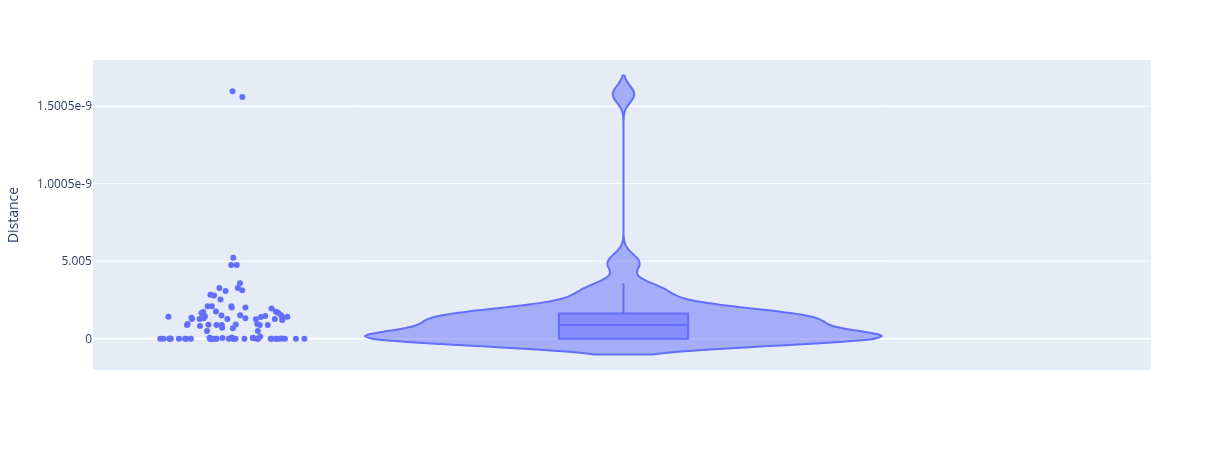
From the above plots, we observe that the samples of the default (non-modified) model, result in 2 reactions with a significantly higher distance than the rest. These are the FRD7 with SUCDi reactions pair. As expected, turning off FRD7 also reduces the distance of SUCDi.